
Abstract
In response to intense pressure, technology companies have enacted policies to combat misinformation1,2,3,4. The enforcement of these policies has, however, led to technology companies being regularly accused of political bias5,6,7. We argue that differential sharing of misinformation by people identifying with different political groups8,9,10,11,12,13,14,15 could lead to political asymmetries in enforcement, even by unbiased policies. We first analysed 9,000 politically active Twitter users during the US 2020 presidential election. Although users estimated to be pro-Trump/conservative were indeed substantially more likely to be suspended than those estimated to be pro-Biden/liberal, users who were pro-Trump/conservative also shared far more links to various sets of low-quality news sites—even when news quality was determined by politically balanced groups of laypeople, or groups of only Republican laypeople—and had higher estimated likelihoods of being bots. We find similar associations between stated or inferred conservatism and low-quality news sharing (on the basis of both expert and politically balanced layperson ratings) in 7 other datasets of sharing from Twitter, Facebook and survey experiments, spanning 2016 to 2023 and including data from 16 different countries. Thus, even under politically neutral anti-misinformation policies, political asymmetries in enforcement should be expected. Political imbalance in enforcement need not imply bias on the part of social media companies implementing anti-misinformation policies.
Similar content being viewed by others
Main
Mass communication is a central feature of modern life, with social media having an increasingly important role in the global distribution and consumption of information16. This increase in importance has been accompanied by increased concern about the part played by social media in the spread of misinformation. For example, both liberals and conservatives in the USA believe technology companies should take action against misinformation17,18, as do many people across European Union member countries19. In response, social media companies have implemented a wide range of anti-misinformation policies in recent years, such as removing or flagging posts deemed to be false by professional fact-checkers20,21,22 or platform users23,24, using ranking algorithms to reduce the likelihood that users see potentially inaccurate posts22,25 and suspending users who spread misinformation3,26,27.
These policies, however, have often led to social media companies being accused of political bias in their choices about who and what to take action against. In the USA, for example, it has been claimed that conservatives and Republicans are purposefully targeted for enforcement because of their political orientation7 (for example, when Donald Trump said that Twitter “totally silences conservatives’ voices”5, or when Representative Jim Jordan charged that academics, social media platforms and the government colluded to censor conservatives28). Accordingly, many social media companies are also very concerned about being perceived as having an anti-conservative bias29, and such concerns may sway the decision-making of such companies. Concerns of bias against conservatives also contributed to Elon Musk’s decision to purchase Twitter in 2022 (ref. 30) and to roll back various anti-misinformation policies (such as reinstating many suspended users)31,32.
Here, we critically examine these allegations of biased treatment. Our argument rests on the following logic: partisan asymmetries in behaviour can lead to partisan asymmetries in treatment, even when the policy is politically neutral and unbiased. For example, if dog-lovers share more misinformation than cat-lovers, we would expect more dog-lovers than cat-lovers to get suspended by social media companies—and would not interpret such a pattern as reflecting bias against dog-lovers.
The same is true when it comes to politics. As we will show here, there is clear evidence of a political asymmetry in misinformation sharing among social media users in the USA—and, crucially, we will use evaluations by politically balanced groups of laypeople to show that this asymmetry cannot be easily attributed to partisan bias on the part of those determining what counts as misinformation. Such asymmetries in sharing do not necessarily imply psychological asymmetries in susceptibility to misinformation, but could instead arise from factors such as asymmetries in exposure to misinformation (for example, from political elites13,33). Whatever their source, these asymmetries in behaviour mean that differential treatment of those on one versus the other side of the aisle does not on its own constitute evidence of political bias on the part of social media companies.
Twitter suspensions after the 2020 election
We begin to shed new empirical light on this issue by taking a specific social media policy choice that has drawn intense criticism as a case study: Twitter’s suspension of users following the 2020 US presidential election. Specifically, in October 2020 we identified 100,000 Twitter users who shared hashtags related to the US presidential election, and randomly sampled 4,500 of those users who shared at least one #VoteBidenHarris2020 hashtag and 4,500 who shared at least one #Trump2020 hashtag. We used each user’s data from that pre-election time period to quantify their tendency to share low-quality news (as well as numerous other potentially relevant characteristics), and then checked 9 months later (after the election season) to determine which users had been suspended by Twitter (for details, see the Methods; data and code are available at https://osf.io/a2t7d/). These data allow us to make several contributions to policy discussions around political bias and anti-misinformation efforts.
First, accusations of political bias are based largely on anecdotes or salient unique cases, such as the suspension of former President Donald Trump. Our data allow us to evaluate these claims more systematically. Indeed, we find that accounts that had shared #Trump2020 during the election were 4.4 times more likely to have been subsequently suspended than those that shared #VoteBidenHarris2020 (χ2(1) = 486.9, P < 0.0001). Specifically, whereas only 4.5% of the users who shared Biden hashtags had been suspended as of July 2021, 19.6% of the users who shared Trump hashtags had been suspended.
Critically, however, this association does not necessarily indicate a causal effect of a user’s politics on suspension—because of the potential for political orientation to be confounded with the tendency to share misinformation (or to engage in other sanctioned behaviours). Indeed, previous work has found consistent evidence of a partisan asymmetry in misinformation sharing: links to websites that journalists and fact-checkers deemed to be low-quality ‘fake news’ sites were shared much more by conservatives than liberals on Facebook during the 2016 election11 and the 2020 election34, and on Twitter during the 2016 election12 and during Donald Trump’s first impeachment35; conservatives on Twitter were much more likely to follow elites that made claims fact-checkers rated as false compared with Democrats13; Republican-oriented images on Facebook were much more likely to be rated as misleading than Democratic-oriented images36; and survey experiments that present participants with politically balanced sets of headlines (removing the supply-side confound present in many observational studies) typically find that conservatives indicate higher sharing intentions for articles deemed to be false by professional fact-checkers than liberals8,9. Furthermore, this association is not limited to the USA. For example, a survey experiment conducted in 16 countries found widespread cross-cultural evidence of conservatives sharing more unambiguously false claims about COVID-19 than liberals37; and an examination of Twitter data found that conservative political elites shared links to lower-quality news sites than liberal political elites in the USA, Germany and the UK33. These observed differences in behaviour have clear implications for differences in treatment by social media platforms.
Low-quality news sharing on Twitter
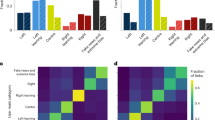
We therefore also examined how the political orientation of the users in our study related to their sharing of links to low-quality news sites in October 2020. We find a similar pattern to past work in our dataset: people who used Trump hashtags shared news from domains that were on average rated as significantly less trustworthy than people who used Biden hashtags. For example, using trustworthiness ratings of 60 news domains (the 20 highest volume sites within each category of mainstream, hyper-partisan and fake news, as determined by fact-checkers and journalists; see Table 1 for a list of the domains used and ref. 38 for details) from 8 professional fact-checkers38, the average quality of domains shared by people who used Trump hashtags was 2.52 s.d. lower than people who used Biden hashtags (t-test, t(8,943) = 1.2 × 102, P < 0.0001; Fig. 1a). We find equivalent results when using a set of 283 domains rated by Ad Fontes Media, Inc. (http://adfontesmedia.com; d = 2.16, t(8,996) = 1.0 × 102, P < 0.0001), 3,216 domains rated by Media Bias/Fact Check (http://mediabiasfactcheck.com; d = 2.06, t(8,997) = 97.6, P < 0.0001) and 4,767 domains rated by aggregating ratings from various fact-checkers and academics33 (d = 2.16, t(8,997) = 1.0 × 102, P < 0.0001) (Extended Data Fig. 1). For further details, see the Methods.

a,b, Distribution of relative frequency of low-quality news sharing scores across people who used the #VoteBidenHarris2020 hashtag versus the #Trump2020 hashtag in our sample of 9,000 Twitter users, on the basis of links shared as of October 2020. The x-axis scores are standardized (z-scored) for comparability; higher values indicate lower-quality news sharing. The y axis indicates relative frequency, such that the area under each curve sums to 1. News site quality ratings as given by 8 professional fact-checkers (a) and news site quality ratings as given by n = 970 laypeople from the USA recruited using Lucid (b), quota-matched to the national distribution on age, gender, education and geographic region; ratings of Democratic respondents and Republican respondents were averaged to create politically balanced layperson ratings. For details of the ratings, see the Methods and ref. 38. c, Top five most-shared news sites among the people in our sample who used Trump versus Biden hashtags, using the list of news sites from ref. 38. d, The correlation between conservatism and low-quality information sharing across seven extra datasets. For x-axis labels, the first row indicates the data source for low-quality news sharing, the second row indicates the source from which the users were sampled, the third row indicates the year in which the data were collected and the fourth row indicates the sample size. For details of each dataset, see Supplementary Information section 3. Error bars indicate 95% confidence intervals. Thus, the pattern observed in panels a and b generalizes beyond Twitter users who shared political hashtags during the 2020 US presidential election to a variety of other contexts.
These results, however, rely on journalists and professional fact-checkers to determine what counts as misinformation. Thus, it is possible that conservatives are found to share more misinformation not because of a true underlying difference in misinformation sharing, but simply because the misinformation evaluators have a liberal bias. To evaluate this possibility, we ask whether a similar pattern of results is observed when using evaluations that are designed to minimize the chance of political bias: trustworthiness ratings generated by politically balanced groups of laypeople. Specifically, we use ratings from a pre-registered study38 in which n = 970 demographically representative (quota-sampled) laypeople from the USA indicated how much they trusted each of the 60 news outlets in Table 1 using a 5-point Likert scale, as well as indicating their preference for the Democratic versus Republican party (6-point Likert scale, with no independent/neutral midpoint; ratings are similar when using party identification and excluding independents38). For each outlet, we then calculated politically balanced layperson ratings by calculating the average trust among people who indicated they preferred the Democrats, and the average trust among people who indicated they preferred the Republicans, and then averaging those two average ratings. Thus, we gave the ratings of people who preferred the Democrats versus Republicans equal weight when constructing our laypeople ratings, and as a result these laypeople ratings cannot reasonably be accused of having liberal bias. See the Methods for further details, and Table 1 for the politically balanced crowd ratings for each domain.
Critically, this unbiased measure produces similar results to those described above using professional fact-checker ratings: when using the ratings of a politically balanced group of laypeople, the average quality of domains shared by people who used Trump hashtags was 2.17 s.d. lower than people who used Biden hashtags (t-test, t(8,943) = 1.0 × 102, P < 0.0001; Fig. 1b). Even when creating a purposefully right-biased quality measure by only using the trustworthiness ratings of Republican laypeople, we still find a qualitatively similar pattern: the average quality of domains shared by people who used Trump hashtags was 1.29 s.d. lower than people who used Biden hashtags (t(8,943) = 61.1, P < 0.0001; Extended Data Fig. 1). To further contextualize the magnitude of this difference, we discretize our politically balanced layperson quality ratings to classify each of the 60 rated domains as low versus high quality (Extended Data Fig. 2), and find that the median Trump hashtag poster shared four times more links to low-quality websites compared with the median Biden hashtag poster.
Our findings are not unique to the use of Biden versus Trump hashtags to classify users’ political orientation: we find high correlations between sharing lower-quality news sources and conservative ideology as estimated on the basis of the Twitter accounts the users follow39 or the news sites that the users share12,40 (expert ratings, 0.73 < r < 0.88 depending on partisanship/ideology measure, P < 0.001 for all; politically balanced layperson ratings, 0.73 < r < 0.82 depending on partisanship/ideology measure, P < 0.001 for all; see the Methods for methodological details).
Broad asymmetries in news sharing quality
This pattern also extends beyond the particular setting of Twitter users during the 2020 election. Across 7 extra datasets, we evaluate the correlation between the average quality of news sources shared (using the set of 60 news sites in Table 1) and political orientation. We find a significant negative relationship of shared news quality and conservatism when examining YouGov respondents’ on-platform Facebook sharing in 2016 (ref. 11) (fact-checker ratings, r(757) = 0.33, P < 0.0001; politically balanced layperson ratings, r(757) = 0.21, P < 0.0001), Prolific respondents’ on-platform Twitter sharing in 2018 (ref. 41) (fact-checker ratings, r(592) = 0.17, P < 0.0001; politically balanced layperson ratings, r(592) = 0.16, P < 0.0001) and 2020 (ref. 41) (fact-checker ratings, r(377) = 0.27, P < 0.0001; politically balanced layperson ratings, r(377) = 0.20, P < 0.0001), and the on-platform sharing of Twitter users sampled in various ways in 2021 (ref. 13) (fact-checker ratings, r(3,068) = 0.57, P < 0.0001; politically balanced layperson ratings (r(3,068) = 0.40, P < 0.0001), 2022 (fact-checker ratings, r(4,038) = 0.40, P < 0.0001; politically balanced layperson ratings, r(4,038) = 0.20, P < 0.0001) and 2023 (fact-checker ratings, r(4,404) = 0.28, P < 0.0001; politically balanced layperson ratings, r(4,404) = 0.14, P < 0.0001) (Fig. 1d). For methodological details, see the Methods; for further analyses, see Supplementary Information section 3.
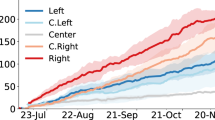
For reasons of tractability, these analyses of posts shared on social media follow the common practice of using domain-level quality ratings as a proxy for information quality rather than examining the actual information contained in each individual post (on the basis of the premise that low-quality news outlets are more likely to publish claims that are false or misleading; see Box 1 for a more detailed discussion regarding different ways of measuring misinformation sharing). Importantly, however, two further analyses of the sharing of posts that specifically contain inaccurate information also find a similar pattern. The first analysis examines the sharing on Twitter of URLs deemed to be inaccurate by either professional fact-checkers or politically balanced layperson ratings, and estimates users’ ideology on the basis of the ideological leaning of the accounts they followed39. Users estimated to be conservative shared significantly more inaccurate URLs than users estimated to be liberal (Wilcoxon signed-rank test, z = 6.641, P < 0.0001 for fact-checker ratings, b = 0.654, P < 0.0001 for layperson ratings; Fig. 2a,b). For methodological details, see the Methods; for further analyses, see Supplementary Information section 3.6 and Extended Data Fig. 3. The second analysis examines a large-scale survey experiment in which participants from 16 countries reported their sharing intentions for a series of COVID-19-related claims (eliminating potential exposure confounds, and presented without source attribution), and conservatism was determined on the basis of responses to two questions about economic conservatism versus liberalism10. Once again, there was a significant correlation between conservatism and average sharing intentions for inaccurate claims (USA: fact-checker ratings, r(439) = 0.11, P = 0.027; politically balanced layperson ratings, r(439) = 0.10, P = 0.029; across all 16 countries: fact-checker ratings, r(7,577) = 0.06, P < 0.0001; politically balanced layperson ratings, r(7,577) = 0.05, P = 0.0001; Fig. 2c,d). For methodological details, see the Methods; for further analyses, see Supplementary Information section 3.7.

a,b, Distribution of the number of Twitter posts containing links to articles rated as false by professional fact-checkers (a), or rated as inaccurate by politically balanced groups of survey respondents (b), made by Twitter users estimated to be liberal versus conservative when analysing data from ref. 53. The y axis shows log10(count of primary posts containing the URL + 1). For details, see the Methods and Supplementary Information section 3.6. c,d, Analysis of sharing intentions for COVID-19 claims from a survey conducted in 16 countries, from ref. 37. Shown is the correlation between self-reported endorsement of conservative economic principles and fraction of shared content that was rated false by fact-checkers (c) or inaccurate by layperson crowds (d). Overall effect was calculated using random effects meta-analysis. Error bars indicate 95% confidence intervals (95% CI). For details, see the Methods and Supplementary Information section 3.7.
Together, these data indicate a consistent pattern whereby conservative or Republican-leaning social media users share more low-quality information—as evaluated by fact-checkers or politically balanced groups of laypeople, and be it judged on the basis of domain-level or post-level ratings—than liberal or Democratic-leaning users. That being said, of course, it is important to keep in mind that people who share content on social media are not representative of the general public, and therefore the consistent pattern we observe here does not necessarily generalize to comparisons of the average liberal versus conservative or Democrat versus Republican; and that the pattern that we observe in these data may be different at other points in time. Our data are also agnostic regarding the extent to which conservatives share more misinformation because they are more psychologically inclined to do so, versus simply being exposed to more misinformation (for example, because, at least during the study period, conservative elites share more misinformation than liberal elites13,33).
News sharing can help explain suspension
Returning to our dataset of Twitter suspensions during the 2020 election, the political asymmetry in sharing low-quality information that we observe may therefore help to explain the apparent preferential suspension of right-leaning users. When we calculate the area under the curve (AUC, which captures accuracy while accounting for differences in base rates and is a standard metric of model performance in fields such as machine learning42), the various measures of sharing low-quality news predict suspension (0.68 < AUC < 0.72) to a similar degree as the various partisanship and ideology measures (0.67 < AUC < 0.71) (Fig. 3a) (no significant difference between average AUC for low-quality news sharing measures versus political orientation measures: bootstrapped 95% confidence interval, −0.005, 0.011). Thus, when examined independently, political orientation and sharing low-quality news are similarly predictive of suspension.

a, When considered separately, political orientation and sharing low-quality information are similarly predictive of suspension. Shown is AUC (a standard measure of predictive accuracy) when predicting whether a user was suspended using models that take different features as the independent variable. Purple bars indicate AUC for measures of political orientation (partisanship on the basis of sharing of #VoteBidenHarris2020 versus #Trump2020 hashtags; ideology on the basis of accounts followed, estimated using the model of ref. 39; ideology on the basis of news sites shared, estimated using the model of ref. 40 or the model of ref. 12). Green bars indicate AUC for measures of sharing links to low-quality news sites on the basis of ratings from Ad Fontes Media (AFM; http://adfontesmedia.com), Media Bias/Fact Check (MBFC; http://mediabiasfactcheck.com), an aggregation of different fact-checkers and journalists33, 8 professional fact-checkers38 and 970 laypeople from the USA, weighting Democrats and Republicans equally38. Error bars indicate bootstrapped 95% confidence intervals. See Extended Data Table 1 for results of regressions jointly considering political orientation, sharing low-quality news links and other controls. b, Simulating a politically neutral anti-misinformation policy—in which there is a constant probability of getting suspended each time a user shares a link to a low-quality news site, as judged by politically balanced groups of laypeople—leads to disparate impact against users on the political right. Shown is the expected probability of suspension for policies that vary in their harshness (that is, in the probability of getting suspended each time a user shares a low-quality link); see the Methods for details. c, Simulating a politically neutral anti-bot policy, in which accounts below a given probability of being human are suspended, shows a similar partisan asymmetry; see the Methods for details.
We also ask what happens when political orientation and sharing low-quality news, along with numerous relevant control variables, are used simultaneously to predict which accounts were suspended during the 6 months after the 2020 US presidential election. To do so, we construct an aggregate measure of the political orientation of the 9,000 politically active Twitter users in our sample by taking the first component of a principal component analysis (PCA) of our four ideology/partisanship measures (on the basis of sharing Trump versus Biden hashtags, the Twitter accounts the users follow39 and the news sites that the users share12,40), and an aggregate measure of sharing low-quality news. We created the latter by taking the first component of a PCA of our 4 expert news site quality measures (60 sites rated by professional fact-checkers38, 283 domains rated by Ad Fontes Media, Inc., 3,216 domains rated by Media Bias/Fact Check and 4,767 domains rated by aggregating ratings from various fact-checkers and academics33). We then use probit regression to predict whether the user was suspended as of the end of July 2021, with P values Holm–Bonferroni corrected to adjust for multiple comparisons (see Supplementary Information section 1 for a full list of control variables and Extended Data Table 1 for regression models). When doing so, the association between political orientation and suspension is not statistically significant (b = 0.12, z = 2.33, PHB = 0.14), whereas sharing low-quality news is positively associated with suspension (b = 0.24, z = 5.18, PHB < 0.001), as are other problematic behaviours such as likelihood of being a bot (estimated using the model from ref. 43; b = 0.20, z = 5.09, PHB < 0.001) and use of toxic language (b = 0.17, z = 6.58, PHB < 0.001); results are similar when using ridge (penalized) regression or logistic regression (Extended Data Table 1).
Of course, because of their correlational nature, these analyses do not allow us to definitively assess whether there was a causal effect of political orientation on Twitter suspensions during the 2020 election. Even if we had more precise measures of misinformation sharing (for example, post-level instead of source-level, or real-time ratings instead of using pre-election tweets to prospectively predict as we do here), or were able to include extra features (for example, harmful content that was deleted before we were able to download it), our estimates could still be biased in either direction by further omitted variables.
Who is sanctioned by unbiased policies
These data do, however, allow us to ask a more general question that has implications beyond just re-litigating the 2020 election cycle in the USA: what would we expect to happen if, theoretically, an entirely politically neutral anti-misinformation policy was implemented? To answer this question, we use simulations to examine which users would have been suspended if suspension had been based only on sharing links to low-quality news sites (using the set of 60 domains rated by laypeople described above38; Extended Data Fig. 2) and not at all on political orientation. That is, by construction we can remove any causal effect of political orientation, and then ask how much of a political asymmetry we nonetheless observe given politically neutral enforcement policies implemented on these data (of course, we do not know what specific policies were actually used by Twitter). To do so, we consider a range of suspension policies that differ in their harshness, for which a given policy specifies the probability of a user getting suspended each time they share a link to a low-quality news domain. For each policy, we can then calculate the average suspension probability of users estimated to be Democrats versus Republicans on the basis of their use of Biden versus Trump hashtags. See the Methods for details.
Using this approach, we find that suspending users for sharing links to news sites deemed to be untrustworthy by politically balanced groups of laypeople38 leads to higher rates of suspension for Republicans than Democrats (Fig. 3b). For example, if users have a 1% chance of getting suspended each time they share a low-quality link, 2.41 times more users who shared Trump hashtags would be suspended compared with users who shared Biden hashtags (d = 0.63; t-test, t(8,998) = 30.1, P < 0.0001). Findings are equivalent when basing suspension on expert assessments of the 60 news sites38, or when correlating predicted suspension rate with ideology (0.31 < r < 0.39, depending on ideology measure; P < 0.0001 for all); see Supplementary Information section 2 for details.
Beyond the sharing of misinformation or conspiracy theories often promoted by low-quality news sites, conservatives in our dataset may also have been preferentially suspended for engaging in other sanctioned behaviours, such as engaging in calls for violence (for example, in connection with the events at the US capital on 6 January 2021, which occurred during our study period), or for using bots. Indeed, as with sharing links to low-quality news sites, users on the political right had significantly higher estimated likelihoods of being a bot (0.70 < r < 0.76 depending on political orientation measure, P < 0.0001 for all; Extended Data Fig. 4), and simulating suspension on the basis of likelihood of being a bot leads to much higher suspension rates for Republican accounts than Democrat accounts (Fig. 3c; see the Methods and Supplementary Information section 2 for details). For example, suspending users with a bot score above 0.5 would lead to 14.2 times more users who shared Trump hashtags getting suspended compared with users who shared Biden hashtags (d = 1.26; t-test, t(8,976) = 59.9, P < 0.0001). Importantly, the associations between political orientation and low-quality news sharing are robust to controlling for bot scores, and to only examining users with low likelihood of being bots (Supplementary Information section 2). Regardless of which prohibited behaviour(s) are in operation, the same fundamental point applies—partisan asymmetries in behaviour can lead to partisan asymmetries in suspension, even when suspension policies are politically neutral.
These analyses show that even in the absence of any (intentional) disparate treatment on the part of technology companies, partisan asymmetries in sanctioned behaviours will lead to (unintentional) disparate impact whereby conservatives are suspended at greater rates. From a legal perspective, political orientation is not a protected class in the USA44 and thus neither form of disparate treatment is illegal (although potentially still normatively undesirable). Although disparate impact may reasonably be considered to constitute discrimination in some cases (for example, employment discrimination on the basis of job-irrelevant factors that correlate with race)45, in the present context reducing the spread of misinformation and the prevalence of bots are legitimate and necessary goals for social media platforms. This makes a normative case for disparate impact on the basis of political orientation.
Social media companies typically do enforcement on the basis of the contents of specific posts, rather than sanctioning users on the basis of the domains they share46,47,48. This post-level approach has the advantage of being much finer grained, as much of the content from low-quality domains may be accurate. Thus, enforcement using domain-level quality will lead to many false positives, in which users are sanctioned for sharing content that is not misinformation. Conversely, post-level sanctions create an incentive for users to not post inaccurate or misleading content in particular. Relatedly, platform sanctions can be deployed at the level of the user (for example, suspending users who post inaccurate content) or the post (for example, attaching warning labels to posts flagged by fact-checkers49), and ranking algorithms—which generally favour content that generates engagement and thus may promote misinformation—can also be tools of anti-misinformation enforcement by downranking content that has been identified as inaccurate (or comes from users who have previously posted inaccurate content).
Asymmetrical treatment need not imply bias
In the context of regulation such as the Digital Services Act recently passed by the European Union—which requires platforms to take down content that involves misinformation—our results suggest that when platforms comply with such regulations, they are likely to face accusations of partisan bias even if their policies are in fact politically neutral. Our results also suggest that using politically balanced groups of laypeople to evaluate content50,51,52 may be a way to identify misinformation while ameliorating charges of political bias. Furthermore, increased transparency on the part of platforms regarding the characteristics (for example, demographics) of users who are getting sanctioned, and why those sanctions are occurring, may help the public better understand how neutral policies can lead to the appearance of bias.
In sum, when there are political asymmetries in misinformation sharing (in either direction), platforms will face a substantial trade-off between reducing the spread of misinformation and being politically balanced in their enforcement. Asymmetric enforcement could also occur outside the context of political orientation (for example, if a particular demographic group is preferentially targeted with misinformation, they may share more of it and thus be sanctioned more frequently). Our argument is not specific to one particular direction of association between political orientation and misinformation sharing—which could potentially be different at different points in time, or for particular topics. If one political, social or demographic group shares more misinformation—be it liberals, conservatives or some other group—it is not possible to be maximally effective in combatting misinformation without preferentially taking action against members of that group. That being said, of course our analyses also do not rule out the possibility of bias on the part of platforms. Instead, we show that asymmetries in treatment are, on their own, not diagnostic of purposeful targeting one way or the other. Be that as it may, given the widespread (and bi-partisan17,18) public demand for reducing misinformation online, policy makers must be aware that some level of differential treatment across groups is likely even if technology companies are working in an unbiased way to keep misinformation in check.
Methods
Sample and basic data collection for 2020 election study
First, we collected a list of Twitter users who tweeted or retweeted either of the election hashtags #Trump2020 and #VoteBidenHarris2020 on 6 October 2020. We also collected the most recent 3,200 tweets sent by each of those accounts. We processed tweets and extracted tweeted domains from 34,920 randomly selected users (15,714 shared #Trump2020 and 19,206 shared #VoteBidenHarris2020), and filtered down to 12,238 users who shared at least five links to domains used by the ideology estimator of ref. 57. We also excluded 426 ‘elite’ users with more than 15,000 followers who are probably unrepresentative of Twitter users more generally (because of this exclusion, suspension data were not collected for these users; however, as described in Supplementary Information section 2, our main results on the association between political orientation and low-quality news sharing are also observed among these elite users). These data were collected as part of a project that was approved by the Massachusetts Institute of Technology Committee on the Use of Humans as Experimental Subjects Protocol 91046.
We then constructed a politically balanced set of users by randomly selecting 4,500 users each from the remaining 4,756 users who shared #Trump2020 and 7,056 users who shared #VoteBidenHarris2020. After 9 months, on 30 July 2021, we checked the status of the 9,000 users and assessed suspension. We classify an account as having been suspended if the Twitter application programming interface (API) returned error code 63 (‘User has been suspended’) when querying that user.
To measure a user’s tendency to share misinformation, we follow most other researchers in this space11,12,58,59 and use news source quality as a proxy for article accuracy, because it is not feasible to rate the accuracy of individual tweets at scale. Specifically, to quantify the quality of news shared by each user, we leveraged a previously published set of 60 news sites (20 mainstream, 20 hyper-partisan 20 fake news; Table 1) whose trustworthiness had been rated by 8 professional fact-checkers as well as politically balanced crowds of laypeople. The crowd ratings were determined as follows. A sample of 971 participants from the USA, quota-matched to the national distribution on age, gender, ethnicity and geographic region, were recruited through Lucid60. Each participant indicated how much they trusted each of the 60 news outlets using a 5-point Likert scale. For each outlet, we then calculated politically balanced crowd ratings by calculating the average trust among Democrats and the average trust among Republicans, and then averaging those two average ratings.
We also examined Reliability ratings for a set of 283 sites from Ad Fontes Media, Inc., Factual Reporting ratings for a set of 3,216 sites from Media Bias/Fact Check and Accuracy ratings for a set of 4,767 sites from a recent academic paper by Lasser et al.33. We then used the Twitter API to retrieve the last 3,200 posts (as of 6 October 2020) for each user in our study, and collected all links to any of those sites shared (tweeted or retweeted) by each user. Following the approach used in previous work58,59, we calculated a news quality score for each user (bounded between 0 and 1) by averaging the ratings of all sites whose links they shared, separately for each set of site ratings. Finally, we transform these ratings into low-quality news sharing scores by subtracting the news quality ratings from 1. Over 99% of users in our study had shared at least one link to a rated domain. When combining the four expert-based measures into an aggregate news quality score, we replaced missing values with the sample mean; PCA indicated that only one component should be retained (87% of variation explained), which had weights of 0.50 on Pennycook and Rand (ref. 38) fact-checker ratings, 0.51 on Ad Fontes Media Reliability ratings, 0.48 on Media Bias/Fact Check Factual Reporting ratings and 0.51 on Lasser et al.33 Accuracy ratings. In all PCA analyses, we use parallel analysis to determine the number of retained components.
To measure a user’s political orientation, we first classify their partisanship on the basis of whether they shared more #Trump2020 or #VoteBidenHarris2020 hashtags. Additionally, we retrieved all accounts followed by users in our sample and used the statistical model from ref. 39 to obtain a continuous measure of users’ ideology on the basis of the ideological leaning of the accounts they followed. Similarly, we used the statistical models from ref. 40 and ref. 12 to estimate users’ ideology using the ideological leanings of the news sites that the users shared content from. We also calculated user ideology by averaging political leanings of domains they shared through tweets or retweets on the basis of the method in ref. 12. The intuition behind these approaches is that users on social media are more likely to follow accounts (and share news stories from sources) that are aligned with their own ideology than those that are politically distant. Thus, the ideology of the accounts the user follows, and the ideology of the news sources the user shares, provide insight into the user’s ideology. When combining these four measures into an aggregate political orientation score, we replaced missing values with the sample mean; PCA indicated that only one component should be retained (88% of variation explained), which had weights of 0.49 on hashtag-based partisanship, 0.49 on follower-based ideology, 0.51 on sharing-based ideology estimated through ref. 40 and 0.51 on sharing-based ideology estimated through ref. 12. We also used this aggregate measure to calculate a user’s extent of ideological extremity by taking the absolute value of the aggregate ideology measure; and we used PCA to combine measures of the standard deviation across a user’s tweets of news site ideology scores from ref. 12 and ref. 40, and standard deviation of ideology of accounts followed from ref. 39, as a measure of the ideological uniformity (versus diversity) of news shared by the user.
Policy simulations
In addition to the regression analyses, we also simulate politically neutral suspension policies and determine each user’s probability of suspension; and from this, determine the level of differential impact we would expect in the absence of differential treatment. The procedure is as follows. First, we identify a set of low-quality sources that could potentially lead to suspension. We do so using the politically balanced layperson trustworthiness ratings from ref. 38, as well as using the fact-checker trustworthiness ratings from that same paper. For both sets of ratings, there is a natural discontinuity at a value of 0.25 (on a normalized trust scale from 0 = Not at all to 1 = Entirely) (Extended Data Fig. 2). Thus, we consider sites with average trustworthiness ratings below 0.25 to be ‘low quality’; and for each user, we count the number of times they tweet links to any of these low-quality sites.
We then define a suspension policy as the probability of a user getting suspended each time they share a link to a low-quality news site. We model suspension as probabilistic because many (almost certainly most) of the articles from low-quality news sites are not actually false, and sharing such articles does not constitute an offence. Thus, we consider who would get suspended under suspension policies that differ in their harshness, varying from a 0.01% chance of getting suspended for each shared link to a low-quality news site up to a 10% chance. Specifically, for each user, we calculate their probability of getting suspended as
where L is the number of low-quality links shared, and k is the probability of suspension for each shared link (that is, the policy harshness). The only way the user would not get suspended is if on each of the L times they share a low-quality link, they are not suspended. Because they do not get suspended with probability (1 − k), the probability that they would never get suspended is (1 − k)L. Therefore, the probability that they would get suspended at some point is 1 − (1 − k)L.
We then calculate the mean (and 95% confidence interval) of that probability across all Democrats versus Republicans in our sample (as determined by sharing Biden versus Trump election hashtags). The results of these analyses are shown in Fig. 3b, and Supplementary Information section 2 presents statistical analyses of estimated probability of suspension on the basis of each measure of political orientation.
We also do a similar exercise using the likelihood of being a bot, rather than low-quality news sharing. The algorithm of ref. 43 provides an estimated probability of being a bot for each user, on the basis of the contents of their tweets. We define a suspension policy as the minimum probability of being human, k, required to avoid suspension (or, in other words, a threshold on bot likelihood above which the user gets suspended). Specifically, for a policy of harshness k, users with bot probability greater than (1 − k) are suspended. The results of these analyses are shown in Fig. 3c.
Reanalyses of extra datasets
Facebook sharing in 2016 by users recruited through YouGov
Here we analyse data presented in ref. 11. A total of n = 1,191 survey respondents recruited using YouGov gave the researchers permission to collect the links they shared on Facebook for 2 months (through a Facebook app), starting in November 2016. As part of the survey, participants self-reported their ideology (using a 5-point Likert scale; not including participants who selected ‘Not sure’, yielding n = 995 respondents with usable ideology data) and their party affiliation (Democrat, Republican, Independent, Other, Not sure). As in our Twitter studies, we calculate low-quality information sharing scores for each user by using the fact-checker and politically balanced crowd ratings for the 60 news sites from ref. 38, as described above in Table 1. A total of 893 participants shared at least one rated link.
Twitter sharing in 2018 and 2020 by users recruited through Prolific
Here we analyse data presented in ref. 41. A total of n = 2,100 participants were recruited using the online labour market Prolific in June 2018. Twitter IDs were provided by participants at the beginning of the study. However, some participants entered obviously fake Twitter IDs—for example, the accounts of celebrities. To screen out such accounts, we followed the original paper and excluded accounts with follower counts above the 95th percentile in the dataset. We had complete data and usable Twitter IDs for 1,901 users. As part of the survey, participants self-reported the extent to which they were economically liberal versus conservative, and socially liberal versus conservative, using 5-point Likert scales. We construct an overall ideology measure by averaging over the economic and social measures. The Twitter API was used to retrieve the content of their last 3,200 tweets (capped by the Twitter API limit). Data were retrieved from Twitter on 18 August 2018, and then again on 12 April 2020 (the latter data pull excludes tweets collected during the former data pull). We calculate low-quality information sharing scores for each user by using the fact-checker and politically balanced crowd ratings for the 60 news sites from ref. 38, as described above in Table 1. A total of 594 participants shared at least one rated link in the 2018 data pull and 379 participants shared at least one rated link in the 2020 data pull; 288 participants shared at least one rated link in both data pulls.
Twitter sharing in 2021 by users who followed at least three political elites
Here we analyse data presented by Mosleh and Rand13, in which Twitter accounts for 816 elites were identified, and then 5,000 Twitter users were randomly sampled from the set of 38,328,679 users who followed at least three of the elite accounts. Each user’s last 3,200 tweets were collected on 23 July 2021, and sharing of low-quality news domains was assessed using the fact-checker and politically balanced crowd ratings from ref. 38. A total of 3,070 users shared at least one rated link. The statistical model from ref. 39 was used to obtain a continuous measure of users’ ideology on the basis of the ideological leaning of the accounts they followed.
Twitter sharing in 2022 by users who followed at least three political elites
Here we analyse previously unpublished data, in which 11,805 Twitter users were sampled from a set of 296,202,962 users who followed at one of the political elite accounts from ref. 41. We randomly sampled from users who had more than 20 lifetime tweets and followed at least three political elites for whom we had a partisanship rating. Each user’s last 3,200 tweets were collected on 25 December 2022, and sharing of low-quality news domains was assessed using the fact-checker and politically balanced crowd ratings from ref. 38. A total of 4,040 users shared at least one rated link. The statistical model from ref. 39 was used to obtain a continuous measure of users’ ideology on the basis of the ideological leaning of the accounts they followed.
Twitter sharing in 2023 by users who followed at least one political elite, stratified on follower count
Here we analyse previously unpublished data in which 11,886 Twitter users were randomly sampled, stratified on the basis of log10-transformed number of followers (rounded to the nearest integer) from the same set of 296,202,962 users who followed at one political elite account. On 4 March 2023, we retrieved all tweets made by each user since 22 December 2022 using the Twitter Academic API. Sharing of low-quality news domains was assessed using the fact-checker and politically balanced crowd ratings from ref. 38. A total of 4,408 users shared at least one rated link. The statistical model from ref. 39 was used to obtain a continuous measure of users’ ideology on the basis of the ideological leaning of the accounts they followed.
Sharing of false claims on Twitter
Here we analyse data from Ghezae et al.53. Unlike the previous analyses, this dataset does not use domain quality as a proxy for misinformation sharing. Instead, sets of specific false versus true headlines were used. The headline sets were assembled by collecting claims that third-party fact-checking websites such as snopes.com or politifact.org had indicated were false, and collecting veridical claims from reputable news outlets. Furthermore, the headlines were pre-tested to determine their political orientation (on the basis of survey respondents’ evaluation of how favourable the headline, if entirely accurate, would be for the Democrats versus Republicans; see ref. 56 for details of the pre-testing procedure).
Survey participants were recruited to rate the accuracy of each URL’s headline claim. Specifically, each participant was shown ten headlines randomly sampled from the full set of headlines, and rated how likely they thought it was that the headline was true using a 9-point scale from ‘not at all likely’ to ‘very likely’. For each headline, we created politically balanced crowd ratings by averaging the accuracy ratings of participants who identified as Democrats, averaging the accuracy ratings of participants who identified as Republicans and then averaging these two average ratings. We then classify URLs as inaccurate (and thus as misinformation) on the basis of crowd ratings if the politically balanced crowd rating was below the accuracy scale midpoint.
Additionally, the Twitter Academic API was used to identify all Twitter users who had posted primary tweets containing each URL. These primary tweets occurred between 2016 and 2022 (2016, 1%; 2017, 2%; 2018, 4%; 2019, 5%; 2020, 34%; 2021, 27%; 2022, 27%). The ideology of each of those users was estimated using the statistical model from ref. 39 on the basis of the ideological leaning of the accounts they followed. This allows us to count the number of liberals and conservatives who shared each URL on Twitter.
The dataset pools across three different iterations of this procedure. The first iteration used 104 headlines selected to be politically balanced, such that the Democrat-leaning headlines were as Democrat-leaning as the Republican-leaning headlines were Republican-leaning; n = 1,319 participants from Amazon Mechanical Turk were then shown a random subset of headlines that were half politically neutral and half aligned with the participant’s partisanship. The second iteration used 155 headlines (of which 30 overlapped with headlines used in the first iteration); n = 853 participants recruited using Lucid rated randomly selected headlines. The third iteration used 149 headlines (no overlap with previous iterations); n = 866 participants recruited using Lucid rated randomly selected headlines. The Amazon Mechanical Turk sample was a pure convenience sample, whereas the Lucid samples were quota-matched to the national distribution on age, gender, ethnicity and geographic region, and then true independents were excluded. For the 30 headlines that overlapped between iterations 1 and 2, the politically balanced crowd accuracy ratings from Amazon Mechanical Turk and Lucid correlated with each other at r(28) = 0.75. Therefore, we collapsed the politically balanced ratings across platforms for those 30 headlines. In total, this resulted in a final dataset with fact-checker ratings, politically balanced crowd ratings and counts of numbers of posts by liberals and conservatives on Twitter for 378 unique URLs.
Finally, we also classified the topic of each URL. To do so, we used Claude, an artificial intelligence system designed by Anthropic that emphasizes reliability and predictability, and has text summarization as one of its primary functions. We uploaded the full set of headlines to the artificial intelligence system, and first asked it to summarize the topics discussed in the headlines. We then asked it to indicate the topic covered in each specific headline, and manually inspected the results to ensure that the classifications were sensible. Next, we examined the frequency of each topic, synthesized the results into a set of six overarching topics and then finally asked the artificial intelligence system to categorize each headline into one of these six topics. This process led to the following distribution of topics: US Politics (174 headlines), Social Issues (91 headlines), COVID-19 (48 headlines), Business/Economy (41 headlines), Foreign Affairs (28 headlines) and Crime/Justice (26 headlines). As a test of the robustness of the classification, we also asked another artificial intelligence system, GPT4, to classify the first 100 headlines into the six topics. We found that Claude and GPT4 agreed on 80% of the headlines.
Sharing intentions of false COVID-19 claims across 16 countries
Here, we examine survey data from ref. 37. In these experiments, participants were recruited from 16 different countries using Lucid, with respondents quota-matched to the national distributions on age and gender in each country. Participants were shown ten false and ten true claims about COVID-19 (sampled from a larger set of 45 claims), presented without any source attribution. The claims were collected from fact-checking organizations in numerous countries, as well as sources such as the World Health Organization’s list of COVID-19 myths. This approach removes ideological variation in exposure to misinformation online13, as well as any potential source cues/effects, and directly measures variation in the decision about what to share.
As in our other analyses, we complement the professional veracity ratings with crowd ratings. Specifically, n = 8,527 participants in the Accuracy condition rated the accuracy of each of the headlines they were shown using a 6-point Likert scale. We calculate the average accuracy rating for each statement in each country, and classify statements as misinformation if that average rating is below the scale midpoint.
Our main analyses then focus on the responses of the n = 8,597 participants from the Sharing condition, in which participants indicated their likelihood of sharing each claim using a 6-point Likert scale. To calculate each user’s level of misinformation sharing, we first discretize the sharing intentions responses such that choices of 1 (Extremely unlikely), 2 (Moderately unlikely) or 3 (Slightly unlikely) on the Likert scale are counted as not shared, whereas choices of 4 (Slightly likely), 5 (Moderately likely) or 6 (Extremely likely) are counted as shared. We then determine, for each user, the fraction of shared articles that were (1) rated as false by fact-checkers, and (2) rated as below the accuracy scale midpoint on average by respondents in the Accuracy condition.
We then ask how misinformation sharing varies with ideology within each country. Specifically, we construct a conservatism measure by averaging responses to two items from the World Values Survey that were included in the survey, which asked how participants would place their views on the scales of ‘Incomes should be made more equal’ versus ‘There should be greater incentives for individual effort’ and ‘Government should take more responsibility to ensure that everyone is provided for’ versus ‘People should take more responsibility to provide for themselves’ using 10-point Likert scales. Pilot data collected in the USA confirmed that responses to these two items correlated with self-report conservatism (r(956) = 0.32 for the first item and r(956) = 0.40 for the second item).
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
All data necessary to reproduce the results are available at https://osf.io/a2t7d/.
Code availability
All scripts necessary to reproduce the results are available at https://osf.io/a2t7d/.
References
Kozyreva, A., Lewandowsky, S. & Hertwig, R. Citizens versus the internet: confronting digital challenges with cognitive tools. Psychol. Sci. Public Interest 21, 103–156 (2020).
Pennycook, G. & Rand, D. G. The psychology of fake news. Trends Cogn. Sci. 25, 388–402 (2021).
Persily, N. & Tucker, J. A. Social Media and Democracy: The State of the Field, Prospects for Reform (Cambridge Univ. Press, 2020).
Kozyreva, A. et al. Toolbox of individual-level interventions against online misinformation. Nat. Hum. Behav. 8, 1044–1052 (2024).
Bond, S. Trump accuses social media of anti-conservative bias after Twitter marks his tweets. npr www.npr.org/2020/05/27/863422722/trump-accuses-social-media-of-anti-conservative-bias-after-twitter-marks-his-twe (2020).
Wermund, B. Ted Cruz digs in for congressional battle over ‘censorship’ on Twitter, Facebook. Houston Chronicle www.houstonchronicle.com/politics/texas/article/Ted-Cruz-digs-in-for-congressional-battle-over-15740624.php (2020).
Vogels, E. A., Perrin, A. & Anderson, M. Most Americans think social media sites censor political viewpoints. Pew Research Center https://www.pewresearch.org/internet/2020/08/19/most-americans-think-social-media-sites-censor-political-viewpoints (2020).
Guay, B., Pennycook, G. & Rand, D. Examining partisan asymmetries in fake news sharing and the efficacy of accuracy prompt interventions. Preprint at PsyArXiv https://doi.org/10.31234/osf.io/y762k (2022).
Pennycook, G. & Rand, D. G. Accuracy prompts are a replicable and generalizable approach for reducing the spread of misinformation. Nat. Commun. 13, 2333 (2022).
Arechar, A. A. et al. Understanding and combatting misinformation across 16 countries on six continents. Nat. Hum. Behav. 7, 1502–1513 (2023).
Guess, A., Nagler, J. & Tucker, J. Less than you think: prevalence and predictors of fake news dissemination on Facebook. Sci. Adv. 5, eaau4586 (2019).
Grinberg, N., Joseph, K., Friedland, L., Swire-Thompson, B. & Lazer, D. Fake news on Twitter during the 2016 US presidential election. Science 363, 374–378 (2019).
Mosleh, M. & Rand, D. G. Measuring exposure to misinformation from political elites on Twitter. Nat. Commun. 13, 7144 (2022).
Nikolov, D., Flammini, A. & Menczer, F. Right and left, partisanship predicts (asymmetric) vulnerability to misinformation. Harvard Kennedy School (HKS) Misinformation Review https://misinforeview.hks.harvard.edu/article/right-and-left-partisanship-predicts-asymmetric-vulnerability-to-misinformation (2021).
DeVerna, M. R., Guess, A. M., Berinsky, A. J., Tucker, J. A. & Jost, J. T. Rumors in retweet: ideological asymmetry in the failure to correct misinformation. Pers. Soc. Psychol. Bull. 50, 3–17 (2024).
Mitchell, A., Jurkowitz, M., Oliphant, J. B. & Shearer, E. Americans who mainly get their news on social media are less engaged, less knowledgeable. Pew Research Center https://www.pewresearch.org/journalism/2020/07/30/americans-who-mainly-get-their-news-on-social-media-are-less-engaged-less-knowledgeable (2020).
Koopman, C. CGO Tech Poll. The Center for Growth and Opportunity at Utah State University https://www.thecgo.org/research/tech-poll (2021).
Atreja, S., Hemphill, L. & Resnick, P. Remove, reduce, inform: what actions do people want social media platforms to take on potentially misleading content? In Proc. ACM on Human-Computer Interaction (ed. Nichols, J.) 1–33 (2023).
Directorate-General for Communication. Flash Eurobarometer 464: Fake News and Disinformation Online. European Union http://data.europa.eu/euodp/en/data/dataset/S2183_464_ENG (2018).
Pennycook, G., Bear, A., Collins, E. T. & Rand, D. G. The implied truth effect: attaching warnings to a subset of fake news headlines increases perceived accuracy of headlines without warnings. Manage. Sci. 66, 4944–4957 (2020).
Clayton, K. et al. Real solutions for fake news? Measuring the effectiveness of general warnings and fact-check tags in reducing belief in false stories on social media. Polit. Behav. 42, 1073–1095 (2020).
Facebook Community Standards—Misinformation. Meta https://transparency.meta.com/en-gb/policies/community-standards/misinformation/ (2024).
Allen, J., Martel, C. & Rand, D. G. Birds of a feather don’t fact-check each other: Partisanship and the evaluation of news in Twitter’s Birdwatch crowdsourced fact-checking program. In Proc. 2022 CHI Conference on Human Factors in Computing Systems (eds Barbosa, S. et al.) 1–19 (2022).
Silverman, H. Meta Newsroom—Helping fact-checkers identify false claims faster. Meta https://about.fb.com/news/2019/12/helping-fact-checkers/ (2019).
Singh, S. & Bagchi, K. How internet platforms are combating disinformation and misinformation in the age of COVID-19. New America www.newamerica.org/oti/reports/how-internet-platforms-are-combating-disinformation-and-misinformation-age-covid-19/facebook/ (2020).
Ortutay, B. & Sweet, K. APNewsBreak: Twitter suspended 58 million accounts in 4Q. APNews https://apnews.com/article/1ee30b22a9ae4267a4e6e5f218bc625b (2018).
Roth, Y. & Harvey, D. How Twitter is fighting spam and malicious automation. X https://blog.x.com/official/en_us/topics/company/2018/how-twitter-is-fighting-spam-and-malicious-automation.html (2018).
Tollefson, J. Disinformation researchers under investigation: what’s happening and why. Nature https://doi.org/10.1038/d41586-023-02195-3 (2023).
Clayton, J. Social media: Is it really biased against US Republicans? BBC www.bbc.co.uk/news/technology-54698186 (2020).
Elon Musk on Real Time with Bill Maher. Elon Musk Interviews https://elon-musk-interviews.com/2023/05/02/real-time-bill-maher-en/ (2023).
Ivanova, I. These formerly banned Twitter accounts have been reinstated since Elon Musk took over. CBS News www.cbsnews.com/news/twitter-accounts-reinstated-elon-musk-donald-trump-kanye-ye-jordan-peterson-kathy-griffin-andrew-tate/ (2022).
The Associated Press. Musk’s Twitter has dissolved its Trust and Safety Council. NPR www.npr.org/2022/12/12/1142399312/twitter-trust-and-safety-council-elon-musk (2022).
Lasser, J. et al. Social media sharing of low-quality news sources by political elites. PNAS Nexus 1, pgac186 (2022).
González-Bailón, S. et al. Asymmetric ideological segregation in exposure to political news on Facebook. Science 381, 392–398 (2023).
Rossetti, M. & Zaman, T. Bots, disinformation, and the first impeachment of US President Donald Trump. PLoS ONE 18, e0283971 (2023).
Yang, Y., Davis, T. & Hindman, M. Visual misinformation on Facebook. J. Commun. 73, 316–328 (2023).
Arechar, A. A. et al. Understanding and combatting misinformation across 16 countries on six continents. Nat. Hum. Behav. 7, 1502–1513 (2023).
Pennycook, G. & Rand, D. G. Fighting misinformation on social media using crowdsourced judgments of news source quality. Proc. Natl Acad. Sci. USA 116, 2521–2526 (2019).
Barberá, P., Jost, J. T., Nagler, J., Tucker, J. A. & Bonneau, R. Tweeting from left to right: is online political communication more than an echo chamber? Psychol. Sci. 26, 1531–1542 (2015).
Eady, G., Nagler, J., Bonneau, R. & Tucker, J. News sharing on social media: mapping the ideology of news media, politicians, and the mass public. Preprint as OSF Preprints https://doi.org/10.31219/osf.io/ch8gj (2020).
Mosleh, M., Pennycook, G., Arechar, A. A. & Rand, D. G. Cognitive reflection correlates with behavior on Twitter. Nat. Commun. 12, 921 (2021).
Huang, J. & Ling, C. X. Using AUC and accuracy in evaluating learning algorithms. IEEE Trans. Knowl. Data Eng. 17, 299–310 (2005).
Social Media Account Classifier. Botsentinel https://botsentinel.com (2022).
The Civil Rights Act of 1964 and the Equal Employment Opportunity Commission. National Archive www.archives.gov/education/lessons/civil-rights-act (2018).
Civil Rights Division. Title IV Legal Manual Section VII: Proving Discrimination – Disparate Impact (U.S. Department of Justice, 2016); www.justice.gov/crt/fcs/T6Manual7.
Facebook Community Standards. Meta https://transparency.fb.com/en-gb/policies/community-standards/ (2024).
Youtube Community Guidelines. YouTube www.youtube.com/howyoutubeworks/policies/community-guidelines/#detecting-violations (2024).
The X Rules. X Help Center https://help.twitter.com/en/rules-and-policies/x-rules (2024).
Martel, C. & Rand, D. G. Misinformation warning labels are widely effective: a review of warning effects and their moderating features. Curr. Opin. Psychol. 54, 101710 (2023).
Allen, J., Arechar, A. A., Pennycook, G. & Rand, D. G. Scaling up fact-checking using the wisdom of crowds. Sci. Adv. 7, eabf4393 (2021).
Godel, W. et al. Moderating with the mob: evaluating the efficacy of real-time crowdsourced fact-checking. J. Online Trust Saf. https://doi.org/10.54501/jots.v1i1.15 (2021).
Resnick, P., Alfayez, A., Im, J. & Gilbert, E. Searching for or reviewing evidence improves crowdworkers’ misinformation judgments and reduces partisan bias. Collect. Intell. https://doi.org/10.1177/26339137231173407 (2023).
Ghezae, I. et al. Partisans neither expect nor receive reputational rewards for sharing falsehoods over truth online. PNAS Nexus 3, pgae287 (2024).
Lin, H. et al. High level of correspondence across different news domain quality rating sets. PNAS Nexus 2, pgad286 (2023).
Allen, J., Watts, D. J. & Rand, D. G. Quantifying the impact of misinformation and vaccine-skeptical content on Facebook. Science 384, eadk3451 (2024).
Pennycook, G., Binnendyk, J., Newton, C. & Rand, D. G. A practical guide to doing behavioral research on fake news and misinformation. Collabra Psychol. https://doi.org/10.1525/collabra.25293 (2021).
Eady, G., Nagler, J., Guess, A., Zilinsky, J. & Tucker, J. A. How many people live in political bubbles on social media? Evidence from linked survey and Twitter data. Sage Open 9, 2158244019832705 (2019).
Pennycook, G. et al. Shifting attention to accuracy can reduce misinformation online. Nature 592, 590–595 (2021).
Mosleh, M., Martel, C., Eckles, D. & Rand, D. G. Perverse downstream consequences of debunking: being corrected by another user for posting false political news increases subsequent sharing of low quality, partisan, and toxic content in a Twitter field experiment. In Proc. 2021 CHI Conference on Human Factors in Computing Systems (eds Kitamura, Y. et al.) 1–13 (2021).
Coppock, A. & McClellan, O. A. Validating the demographic, political, psychological, and experimental results obtained from a new source of online survey respondents. Res. Politics 6, 2053168018822174 (2019).
Acknowledgements
We thank A. Guess and I. Ghezae for assistance in our re-analysis of data from the papers on which they are lead authors. We thank A. Bear and B. Tappin for constructive feedback that improved this work.
Author information
Authors and Affiliations
Contributions
M.M. and D.G.R. designed the study. M.M. and Q.Y. collected the data. M.M. and D.G.R. analysed the results. D.G.R. and G.P. wrote the paper with input from T.Z. and M.M.
Corresponding author
Ethics declarations
Competing interests
M.M., D.G.R. and G.P. have received funding from Meta and Google to conduct research related to reducing the spread of misinformation online and identifying inauthentic accounts. G.P. was a Faculty Research Fellow at Google in 2022. D.G.R. was an unpaid consultant for Twitter in 2021 and 2022. Q.Y. was an intern at Snapchat in 2020, and worked at Meta 2021–2023.
Peer review
Peer review information
Nature thanks Adela Levis, Sander van der Linden, Yunkang Yang, David Yokum, Alix Zwane and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data figures and tables
Extended Data Fig. 1 Twitter users who used Trump hashtags shared links to lower quality news sites than Twitter users who used Biden hashtags, regardless of which set of quality ratings are used.
Low Quality News Site Sharing scores by partisanship using alternative quality rating sets. Scores are standardized (z-scored) for comparability; higher values indicate lower quality news sharing.
Extended Data Fig. 2 News quality ratings from Pennycook & Rand (2019).
Ratings generated by politically balanced crowds of laypeople (y-axis) and professional fact-checkers (x-axis). News sources shown as orange diamonds are counted as low quality for simulating suspensions.
Extended Data Fig. 3 No evidence of topics for which liberals on Twitter share more links to false articles than conservatives.
Further analysis of the number of posts containing misinformation links shared by liberals versus conservatives on Twitter when analyzing data from Ref. 53. Shown is the coefficient on an ideology dummy in a linear regression predicting log10(# misinformation shares +1) separately for URLs of each topic, along with the overall estimate from a random effects meta-analysis. Top panel shows results when considering URLs rated as false by professional fact-checkers; bottom panel shows results when considering URLs rated as inaccurate by politically-balanced crowds.
Extended Data Fig. 4 Twitter users who used Trump hashtags are rated as more likely to be bots than Twitter users who used Biden hashtags.
Bot Sentinel43 scores for the Twitter users in our 2020 election study, by partisanship (estimated based on whether users shared more Biden versus Trump hashtags).
Supplementary information
Supplementary Information
Supplementary methods, results, Tables 1 and 2 and references.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Mosleh, M., Yang, Q., Zaman, T. et al. Differences in misinformation sharing can lead to politically asymmetric sanctions. Nature 634, 609–616 (2024). https://doi.org/10.1038/s41586-024-07942-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41586-024-07942-8
This article is cited by
-
Does fact-checking work? What the science says
Nature (2025)
